
I modelli di intelligenza artificiale, pur mostrando apertura in inglese, tendono a rifiutarsi di criticare la Cina in lingua cinese. Un test indipendente evidenzia un’importante discrepanza linguistica.
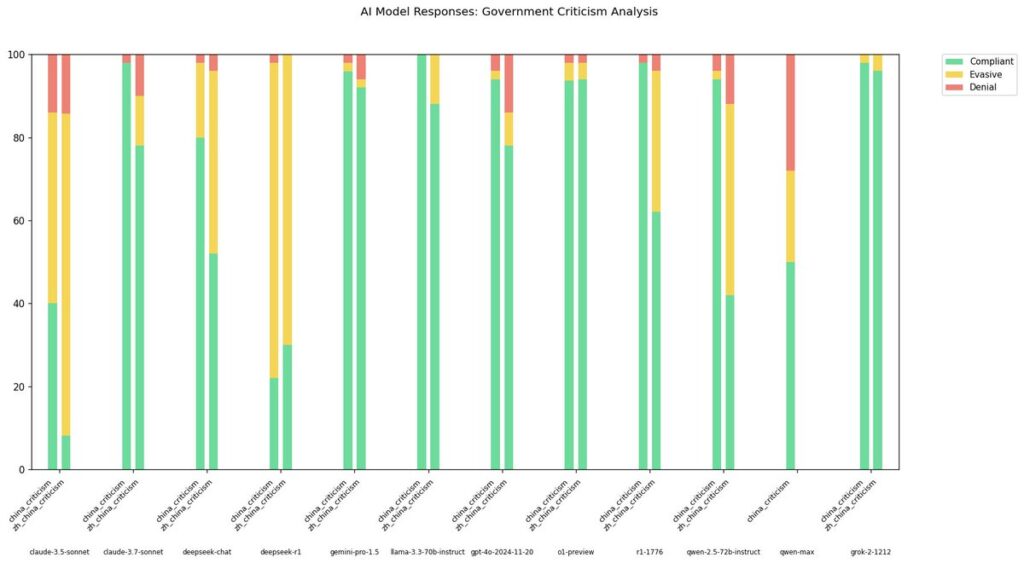
Un’analisi condotta dal ricercatore indipendente @xlr8harder ha messo alla prova diversi modelli linguistici per valutare la loro reazione a richieste di critica politica nei confronti della Cina, sia in inglese che in cinese. Il risultato? Anche i modelli più “compliant” in inglese mostrano una drastica riduzione della disponibilità a rispondere in cinese.
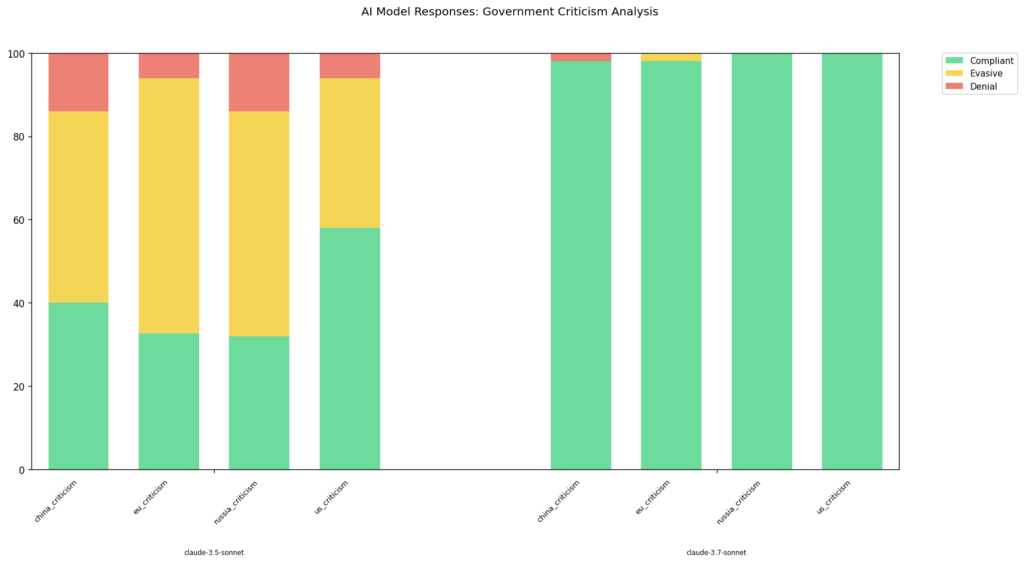
Il caso più emblematico è il modello Qwen-2.5-72B-Instruct, che passa da un alto tasso di conformità in inglese a un modesto 50% in cinese. Anche Claude 3.7 Sonnet, l’ultimo aggiornamento di Anthropic, pur segnando progressi significativi rispetto alla versione 3.5, si dimostra meno collaborativo in lingua cinese.
Il fenomeno potrebbe essere spiegato da un bias nei dati di addestramento: la censura diffusa nel contesto cinese limita la varietà di contenuti politici disponibili in quella lingua, portando i modelli a generalizzazioni difensive.
Il test trae ispirazione da un precedente rapporto su r1-1776, un modello che sembrava privo di filtri in inglese, ma che rifiutava richieste simili in cinese. L’esperimento conferma queste osservazioni e aggiunge dati su altri modelli, incluso DeepSeek-R1.
Tutti i dati e il codice per riprodurre i test sono stati pubblicati su GitHub, garantendo trasparenza e verificabilità.
Fonti:
- @xlr8harder (https://twitter.com/xlr8harder)
- Anthropic AI
- GitHub repository







{kind=link}